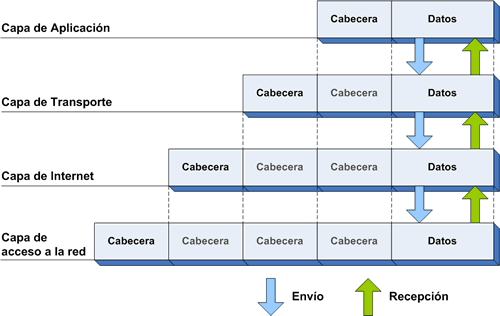
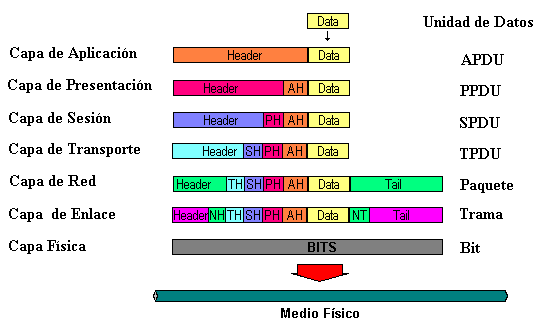
Tecnologias WWW:
En informática,
la World Wide Web (WWW) o Red informática mundial
es un sistema de distribución de información basado en hipertexto o hipermedios enlazados
y accesibles a través de Internet.
Con un navegador web,
un usuario visualiza sitios web compuestos de páginas web que pueden contener texto, imágenes, vídeos u otros contenidos multimedia,
y navega a través de ellas usando hiperenlaces.
La Web fue creada
alrededor de 1989 por el inglés Tim Berners-Lee con la ayuda del belga Robert Cailliau mientras trabajaban en
el CERN en Ginebra, Suiza,
y publicado en 1992.
Desde entonces, Berners-Lee ha jugado un papel activo guiando el desarrollo de estándares
Web (como los lenguajes de marcado con
los que se crean las páginas web), y en los últimos años ha abogado por su
visión de una Web semántica.
Funcionamiento
El primer paso consiste
en traducir la parte nombre del servidor de la URL en una dirección IP usando la base de datos
distribuida de Internet conocida como DNS.
Esta dirección IP es necesaria para contactar con el servidor web y poder enviarle paquetes de datos.
El siguiente paso es
enviar una petición HTTP al servidor Web solicitando
el recurso. En el caso de una página web típica, primero se solicita el texto HTML y luego es
inmediatamente analizado por el navegador, el cual, después, hace peticiones
adicionales para los gráficos y otros ficheros que formen parte de la página.
Las estadísticas de popularidad de un sitio web normalmente están basadas en el
número de páginas vistas o las peticiones de servidor asociadas, o
peticiones de fichero, que tienen lugar.
Al recibir los ficheros
solicitados desde el servidor web, el navegador renderiza la página tal y como se describe en el
código HTML, el CSS y otros lenguajes web.
Al final se incorporan las imágenes y otros recursos para producir la página
que ve el usuario en su pantalla.
Historia
La idea subyacente de la
Web se remonta a la propuesta de Vannevar Bush en los años 40 sobre un sistema
similar: a grandes rasgos, un entramado de información distribuida con una
interfaz operativa que permitía el acceso tanto a la misma como a otros
artículos relevantes determinados por claves. Este proyecto nunca fue materializado,
quedando relegado al plano teórico bajo el nombre de Memex. Es en los años 50 cuando Ted Nelson realiza la primera
referencia a un sistema de hipertexto, donde la información es enlazada de
forma libre. Pero no es hasta 1980,
con un soporte operativo tecnológico para la distribución de información en redes
informáticas, cuando Tim Berners-Lee propone ENQUIRE al CERN (refiriéndose a Enquire Within Upon Everything,
en castellano Preguntando de Todo Sobre Todo),
donde se materializa la realización práctica de este concepto de incipientes
nociones de la Web.
En marzo de 1989,
Tim Berners Lee, ya como personal de la división DD del CERN, redacta la
propuesta, que referenciaba a
ENQUIRE y describía un sistema de gestión de información más elaborado. No hubo
un bautizo oficial o un acuñamiento del término web en esas referencias
iniciales, utilizándose para tal efecto el término mesh.
Sin embargo, el World Wide Web ya había nacido. Con la ayuda de Robert Cailliau,
se publicó una propuesta más formal para la world wide web el 6 de agosto de 1991.
Berners-Lee usó un NeXTcube como
el primer servidor web del mundo y también
escribió el primer navegador web, WorldWideWeb en 1991. En las Navidades del mismo
año, Berners-Lee había creado todas las herramientas necesarias para que una
web funcionase: el primer navegador web
(el cual también era un editor web), el primer servidor web y las primeras
páginas web que al mismo tiempo
describían el proyecto.
El 6 de agosto de 1991,
envió un pequeño resumen del proyecto World Wide Web al newsgroup alt.hypertext. Esta fecha también
señala el debut de la web como un servicio disponible públicamente en Internet.
El concepto, subyacente
y crucial, del hipertexto tiene sus orígenes en
viejos proyectos de la década de los 60,
como el Proyecto Xanadu de Ted Nelson y el sistema on-line NLS de Douglas Engelbart.
Los dos, Nelson y Engelbart, estaban a su vez inspirados por el ya citado
sistema basado en microfilm "memex", de Vannevar Bush.
El gran avance de
Berners-Lee fue unir hipertexto e Internet. En su libro Weaving
the Web (en castellano,
Tejiendo la Red), explica que él había sugerido repetidamente que la unión
entre las dos tecnologías era posible para miembros de las dos comunidades tecnológicas, pero como
nadie aceptó su invitación, decidió, finalmente, hacer frente al proyecto él
mismo. En el proceso, desarrolló un sistema de identificadores únicos globales para los recursos web y
también: el Uniform Resource Identifier.
World Wide Web tenía
algunas diferencias de los otros sistemas de hipertexto que estaban disponibles
en aquel momento:
<!--[if !supportLists]-->§
<!--[endif]-->WWW sólo requería enlaces unidireccionales en vez de los
bidireccionales. Esto hacía posible que una persona enlazara a otro recurso sin
necesidad de ninguna acción del propietario de ese recurso. Con ello se reducía
significativamente la dificultad de implementar servidores web y navegadores
(en comparación con los sistemas anteriores), pero en cambio presentaba el
problema crónico de los enlaces rotos.
<!--[if !supportLists]-->§
<!--[endif]-->A diferencia de sus predecesores, como HyperCard, World
Wide Web era no-propietario, haciendo posible desarrollar servidores y clientes
independientemente y añadir extensiones sin restricciones de licencia.
El 30 de abril de 1993,
el CERN anunció que la web sería
gratuita para todos, sin ningún tipo de honorarios.
Viola WWW fue un navegador
bastante popular en los comienzos de la web que estaba basado en el concepto de
la herramienta hipertextual de software de Mac denominada HyperCard. Sin
embargo, los investigadores generalmente están de acuerdo en que el punto de
inflexión de la World Wide Web comenzó con la introducción del navegador web Mosaic en
1993, un navegador gráfico desarrollado por un equipo del NCSA en la Universidad de Illinois en Urbana-Champaign (NCSA-UIUC), dirigido
por Marc Andreessen.
El apoyo para desarrollar Mosaic vino del High-Performance Computing and
Communications Initiative, un programa de fondos iniciado por el
entonces gobernador Al Gore en el High
Performance Computing and Communication Act of 1991,
también conocida como la Gore Bill. Antes del lanzamiento de
Mosaic, las páginas web no integraban un amplio entorno gráfico y su
popularidad fue menor que otros protocolos anteriores ya en uso sobre Internet,
como el protocolo Gopher y WAIS.
La interfaz gráfica de usuario de Mosaic permitió a la WWW convertirse en el
protocolo de Internet más popular de una manera fulgurante...
Java y JavaScript
Un avance significativo
en la tecnología web fue la Plataforma Java de Sun Microsystems.
Este lenguaje permite que las páginas web contengan pequeños programas
(llamados applets) directamente en la visualización.
Estos applets se ejecutan en el ordenador del usuario, proporcionando un
interfaz de usuario más rico que simples páginas web.
JavaScript,
en cambio, es un lenguaje de script que
inicialmente fue desarrollado para ser usado dentro de las páginas web. La
versión estandarizada es el ECMAScript. Si bien
los nombres son similares, JavaScript fue desarrollado por Netscape y no tiene relación
alguna con Java, aparte de que sus sintaxis derivan del lenguaje de programación C.
En unión con el Document Object Model de
una página web, JavaScript se ha convertido en una tecnología mucho más importante
de lo que pensaron sus creadores originales. La manipulación del Modelo de
Objetos de Documento después de que la página ha sido enviada al cliente se ha
denominado HTML Dinámico (DHTML), para enfatizar
un cambio con respecto a las visualizaciones de HTML estático.
Estándares
Destacamos los
siguientes estándares:
<!--[if !supportLists]-->§
<!--[endif]-->el Identificador de Recurso Uniforme (URI), que es un sistema
universal para referenciar recursos en la Web, como páginas web,
<!--[if !supportLists]-->§
<!--[endif]-->el Protocolo de Transferencia de Hipertexto (HTTP),
que especifica cómo se comunican el navegador y el servidor entre ellos,
- Hypertext Transfer
Protocol (HTTP) (en español, Protocolo de Transferencia de
Hipertexto)
- RFC 1945, Especificación de HTTP/1.0 (Mayo de 1996)
- RFC 2616, Especificación de HTTP/1.1 (Junio de 1999)
- RFC 2617, Autenticación HTTP
- HTTP/1.1
Especificación de errores de HTTP/1.1
<!--[if !supportLists]-->§
<!--[endif]-->el Lenguaje de Marcado de Hipertexto (HTML),
usado para definir la estructura y contenido de documentos de hipertexto,
- Hypertext Markup Language
(HTML) (en español, Lenguaje de Etiquetado de Hipertexto)
- Internet Draft, HTML
version 1
- RFC 1866, HTML version 2.0
- Referencia
de la especificación HTML 3.2
- Especificación
de HTML 4.01
- Especificación
de HTML5
- Especificación
de HTML Extensible (XHTML)1.0
- Especificación
de HTML Extensible (XHTML)1.1
<!--[if !supportLists]-->§
<!--[endif]-->el Lenguaje de Marcado Extensible (XML),
usado para describir la estructura de los documentos de texto.
- Uniform Resource Locators
(URL) (en español, Localizador de Recursos Uniforme)
- RFC 1738, Localizador de Recursos Uniforme (URL) (Diciembre de 1994)
- RFC 3986, Uniform Resource Identifier (URI) (en castellano, Identificador de
Recursos Uniforme): Sintaxis general (Enero de 2005)
Berners Lee dirige desde 2007 el World Wide Web Consortium (W3C),
el cual desarrolla y mantiene esos y otros estándares que permiten a los ordenadores
de la Web almacenar y comunicar efectivamente diferentes formas de información.
Las tecnologías web
implican un conjunto de herramientas que nos facilitarán lograr mejores
resultados a la hora del desarrollo de un sitio web.
Navegadores
web
<!--[if !supportLists]-->§
<!--[endif]-->Mozilla Firefox
<!--[if !supportLists]-->§
<!--[endif]-->Google Chrome
<!--[if !supportLists]-->§
<!--[endif]-->Amaya
<!--[if !supportLists]-->§
<!--[endif]-->Epiphany
<!--[if !supportLists]-->§
<!--[endif]-->Galeon
<!--[if !supportLists]-->§
<!--[endif]-->Konqueror sobre linux
<!--[if !supportLists]-->§
<!--[endif]-->Lynx sobre
linux
<!--[if !supportLists]-->§
<!--[endif]-->Opera
<!--[if !supportLists]-->§
<!--[endif]-->Safari
<!--[if !supportLists]-->§
<!--[endif]-->Seamonkey
<!--[if !supportLists]-->§
<!--[endif]-->Shiira
<!--[if !supportLists]-->§
<!--[endif]-->Flock
<!--[if !supportLists]-->§
<!--[endif]-->Arora
<!--[if !supportLists]-->§
<!--[endif]-->K-Meleon
Servidores
web
<!--[if !supportLists]-->§
<!--[endif]-->IIS
<!--[if !supportLists]-->§
<!--[endif]-->FTP
Otras
tecnologías
<!--[if !supportLists]-->§
<!--[endif]-->OAI-PMH
<!--[if !supportLists]-->§
<!--[endif]-->CFM Coldfusion
<!--[if !supportLists]-->§
<!--[endif]-->DHTML
<!--[if !supportLists]-->§
<!--[endif]-->PHP
<!--[if !supportLists]-->§
<!--[endif]-->ASP
<!--[if !supportLists]-->§
<!--[endif]-->CGI
<!--[if !supportLists]-->§
<!--[endif]-->JSP (Tecnología Java )
<!--[if !supportLists]-->§
<!--[endif]-->.NET
Tipología web
<!--[if !supportLists]-->§
<!--[endif]-->Bitácora o Weblog / Blog
<!--[if !supportLists]-->§
<!--[endif]-->Wiki
<!--[if !supportLists]-->§
<!--[endif]-->Web
2.0
Comunicación inalámbrica:
Aspecto histórico y generalidades
La comunicación
inalámbrica, que se realiza a través de ondas de radiofrecuencia, facilita la operación en lugares
donde la computadora no se encuentra en una ubicación fija (almacenes, oficinas
de varios pisos, etc.) actualmente se utiliza de una manera general y accesible
para todo público. Cabe también mencionar actualmente que las redes cableadas
presentan ventaja en cuanto a transmisión de datos sobre las inalámbricas. Mientras
que las cableadas proporcionan velocidades de hasta 1Gbps (Red Gigabit),
las inalámbricas alcanzan sólo hasta 108 Mbps.
Se puede realizar una
“mezcla” entre inalámbricas y alámbricas, de manera que pueden funcionar de la
siguiente manera: que el sistema cableado sea la parte principal y la
inalámbrica sea la que le proporcione movilidad al equipo y al operador para
desplazarse con facilidad en distintos campo (almacén u oficina).
Actualmente, las
transmisiones inalámbricas constituyen una eficaz herramienta que permite la
transferencia de voz, datos y vídeo sin la necesidad de
cableado. Esta transferencia de información es lograda a través de la emisión
de ondas de radio teniendo dos ventajas: movilidad y flexibilidad del sistema
en general.
Aspectos tecnológicos
En general, la
tecnología inalámbrica utiliza ondas de radiofrecuencia de baja potencia y una banda específica,
de uso libre o privada para transmitir, entre dispositivos.
Estas condiciones de
libertad de utilización sin necesidad de licencia, ha propiciado que el número de equipos, especialmente
computadoras, que utilizan las ondas para conectarse, a través deredes inalámbricas haya crecido
notablemente.
Campos de utilización
La tendencia a la
movilidad y la ubicuidad hacen que cada vez sean más utilizados los sistemas
inalámbricos, y el objetivo es ir evitando los cables en todo tipo de
comunicación, no solo en el campo informático sino en televisión, telefonía,
seguridad, domótica, etc.
Un fenómeno social que
ha adquirido gran importancia, en todo el mundo, como consecuencia del uso de
la tecnología inalámbrica son las comunidades inalámbricas que buscan la difusión
de redes alternativas a las comerciales. El mayor exponente de esas iniciativas
en España es RedLibre.
Algunos problemas asociados con la
tecnología inalámbrica
Los hornos de microondas utilizan radiaciones en
el espectro de 2,45 Ghz. Es por ello que las
redes y teléfonos inalámbricos que utilizan el espectro de 2,4 Ghz. pueden
verse afectados por la proximidad de este tipo de hornos, que pueden producir
interferencias en las comunicaciones.
Otras veces, este tipo
de interferencias provienen de una fuente que no es accidental. Mediante el uso
de un perturbador o inhibidor de señal se puede
dificultar e incluso imposibilitar las comunicaciones en un determinado rango
de frecuencias.
Equipo inalámbrico
Algunos de los equipos
de punto de acceso que normalmente vienen con antena omni 2 Dbi, muchas veces
desmontables, en las cuales se puede hacer enlaces por encima de los 500 metros
y además se pueden interconectar entre sí. No debe haber obstáculos para que la
señal sea excelente, ya que esto interfiere en la señal y puede haber problemas
en la conexión.
Seguridad
informática:
La seguridad informática,
es el área de la informática que se enfoca en la
protección de la infraestructura computacional y todo lo relacionado con esta
(incluyendo la información contenida). Para ello existen una serie de
estándares, protocolos, métodos, reglas, herramientas y leyes concebidas para
minimizar los posibles riesgos a la infraestructura o a la información. La
seguridad informática comprende software, bases de datos, metadatos, archivos y
todo lo que la organización valore (activo) y signifique un riesgo si ésta
llega a manos de otras personas. Este tipo de información se conoce como
información privilegiada o confidencial.
El concepto de seguridad
de la información no debe ser confundido con el de seguridad
informática, ya que este último sólo se encarga de la seguridad en el medio
informático, pudiendo encontrar información en diferentes medios o formas.
La seguridad informática es la
disciplina que se ocupa de diseñar las normas, procedimientos, métodos y
técnicas destinados a conseguir un sistema de información seguro y confiable.
Objetivos
de la seguridad informática
La seguridad informática está
concebida para proteger los activos informáticos, entre los que se encuentran.
<!--[if !supportLists]-->§
<!--[endif]-->La información contenida
<!--[if !supportLists]-->§
<!--[endif]-->La infraestructura computacional.
<!--[if !supportLists]-->§
<!--[endif]-->Los usuarios
Una vez que la programación y el
funcionamiento de un dispositivo de almacenamiento (o transmisión) de la
información se consideran seguras, todavía deben ser tenidos en cuenta las
circunstancias "no informáticas" que pueden afectar a los datos, las
cuales son a menudo imprevisibles o inevitables, de modo que la única
protección posible es la redundancia (en el caso de los datos) y la
descentralización -por ejemplo mediante estructura de redes- (en el caso de las
comunicaciones).
Estos fenómenos pueden ser causados
por:
<!--[if !supportLists]-->§ <!--[endif]-->El usuario: causa del mayor problema ligado
a la seguridad de un sistema informático (porque no le importa, no se da cuenta
o a propósito).
<!--[if !supportLists]-->§ <!--[endif]-->Programas maliciosos: programas destinados a
perjudicar o a hacer un uso ilícito de los recursos del sistema. Es instalado
(por inatención o maldad) en el ordenador abriendo una puerta a intrusos o bien
modificando los datos. Estos programas pueden ser un virus informático, un
gusano informático, un troyano, una bomba lógica o un programa espía o Spyware.
<!--[if !supportLists]-->§ <!--[endif]-->Un intruso: persona que consigue acceder a
los datos o programas de los cuales no tiene acceso permitido (cracker,
defacer, script kiddie o Script boy, viruxer, etc.).
<!--[if !supportLists]-->§ <!--[endif]-->Un siniestro (robo, incendio, inundación):
una mala manipulación o una malintención derivan a la pérdida del material o de
los archivos.
<!--[if !supportLists]-->§ <!--[endif]-->El personal interno de Sistemas. Las pujas de poder que llevan a
disociaciones entre los sectores y soluciones incompatibles para la seguridad
informática.
El hecho de conectar una red a un
entorno externo nos da la posibilidad de que algún atacante pueda entrar en
ella, con esto, se puede hacer robo de información o alterar el funcionamiento
de la red. Sin embargo el hecho de que la red no sea conectada a un entorno
externo no nos garantiza la seguridad de la misma. De acuerdo con el Computer
Security Institute (CSI) de San Francisco aproximadamente entre 60 y 80 por
ciento de los incidentes de red son causados desde adentro de la misma. Basado
en esto podemos decir que existen 2 tipos de amenazas:
<!--[if !supportLists]-->§ <!--[endif]-->Amenazas internas: Generalmente
estas amenazas pueden ser más serias que las externas por varias razones como
son:
-Los usuarios conocen la red y
saben cómo es su funcionamiento.
-Tienen algún nivel de acceso a
la red por las mismas necesidades de su trabajo.
-Los IPS y Firewalls son
mecanismos no efectivos en amenazas internas.
El resultado es la violación de
los sistemas, provocando la pérdida o modificación de los datos sensibles de la
organización, lo que puede representar un daño con valor de miles o millones de
dólares.
<!--[if !supportLists]-->§ <!--[endif]-->Amenazas externas: Son aquellas
amenazas que se originan fuera de la red. Al no tener información certera de la
red, un atacante tiene que realizar ciertos pasos para poder conocer qué es lo
que hay en ella y buscar la manera de atacarla. La ventaja que se tiene en este
caso es que el administrador de la red puede prevenir una buena parte de los
ataques externos.
Los virus se pueden clasificar de
la siguiente forma:
Virus residentes
La característica principal de
estos virus es que se ocultan en la memoria RAM de forma permanente o
residente. De este modo, pueden controlar e interceptar todas las operaciones
llevadas a cabo por el sistema operativo, infectando todos aquellos ficheros
y/o programas que sean ejecutados, abiertos, cerrados, renombrados, copiados.
Algunos ejemplos de este tipo de virus son: Randex, CMJ, Meve, MrKlunky.
Virus de acción directa
Al contrario que los residentes,
estos virus no permanecen en memoria. Por tanto, su objetivo prioritario es
reproducirse y actuar en el mismo momento de ser ejecutados. Al cumplirse una
determinada condición, se activan y buscan los ficheros ubicados dentro de su
mismo directorio para contagiarlos.
Virus de sobreescritura
Estos virus se caracterizan por
destruir la información contenida en los ficheros que infectan. Cuando infectan
un fichero, escriben dentro de su contenido, haciendo que queden total o
parcialmente inservibles.
Virus de boot(bot_kill) o de
arranque
Los términos boot o sector de
arranque hacen referencia a una sección muy importante de un disco o unidad de
almacenamiento CD,DVD, memorias USB etc. En ella se guarda la información
esencial sobre las características del disco y se encuentra un programa que
permite arrancar el ordenador. Este tipo de virus no infecta ficheros, sino los
discos que los contienen. Actúan infectando en primer lugar el sector de
arranque de los dispositivos de almacenamiento. Cuando un ordenador se pone en
marcha con un dispositivo de almacenamiento, el virus de boot infectará a su
vez el disco duro.
Los virus de boot no pueden
afectar al ordenador mientras no se intente poner en marcha a éste último con
un disco infectado. Por tanto, el mejor modo de defenderse contra ellos es
proteger los dispositivos de almacenamiento contra escritura y no arrancar
nunca el ordenador con uno de estos dispositivos desconocido en el ordenador.
Algunos ejemplos de este tipo de
virus son: Polyboot.B, AntiEXE.
Virus de enlace o directorio
Los ficheros se ubican en
determinadas direcciones (compuestas básicamente por unidad de disco y
directorio), que el sistema operativo conoce para poder localizarlos y trabajar
con ellos.
Virus cifrados
Más que un tipo de virus, se
trata de una técnica utilizada por algunos de ellos, que a su vez pueden
pertenecer a otras clasificaciones. Estos virus se cifran a sí mismos para no
ser detectados por los programas antivirus. Para realizar sus actividades, el
virus se descifra a sí mismo y, cuando ha finalizado, se vuelve a cifrar.
Virus polimórficos
Son virus que en cada infección
que realizan se cifran de una forma distinta (utilizando diferentes algoritmos
y claves de cifrado). De esta forma, generan una elevada cantidad de copias de
sí mismos e impiden que los antivirus los localicen a través de la búsqueda de
cadenas o firmas, por lo que suelen ser los virus más costosos de detectar.
Virus multipartites
Virus muy avanzados, que pueden
realizar múltiples infecciones, combinando diferentes técnicas para ello. Su
objetivo es cualquier elemento que pueda ser infectado: archivos, programas,
macros, discos, etc.
Virus del Fichero
Infectan programas o ficheros
ejecutables (ficheros con extensiones EXE y COM). Al ejecutarse el programa
infectado, el virus se activa, produciendo diferentes efectos.
Virus de FAT
La Tabla de Asignación de
Ficheros o FAT es la sección de un disco utilizada para enlazar la información
contenida en éste. Se trata de un elemento fundamental en el sistema. Los virus
que atacan a este elemento son especialmente peligrosos, ya que impedirán el
acceso a ciertas partes del disco, donde se almacenan los ficheros críticos
para el normal funcionamiento del ordenador.
de seguridad informática.
Técnicas para asegurar el sistema
<!--[if !supportLists]-->§ <!--[endif]-->Codificar la información: Criptología, Criptografía y Criptociencia, contraseñas
difíciles de averiguar a partir de datos personales del individuo.
La información constituye el
activo más importante de las empresas, pudiendo verse afectada por muchos
factores tales como robos, incendios, fallas de disco, virus u otros. Desde el
punto de vista de la empresa, uno de los problemas más importantes que debe
resolver es la protección permanente de su información crítica.
La medida más eficiente para la
protección de los datos es determinar una buena política de copias de seguridad
o backups: Este debe incluir copias de seguridad completa (los datos son almacenados
en su totalidad la primera vez) y copias de seguridad incrementales (sólo se
copian los ficheros creados o modificados desde el último backup). Es vital
para las empresas elaborar un plan de backup en función del volumen de
información generada y la cantidad de equipos críticos.
Un buen sistema de respaldo debe
contar con ciertas características indispensables:
Continuo
El respaldo de datos debe ser completamente
automático y continuo. Debe funcionar de forma transparente, sin intervenir en
las tareas que se encuentra realizando el usuario.
Seguro
Muchos softwares de respaldo incluyen cifrado de
datos (128-448 bits), lo cual debe ser hecho localmente en el equipo antes del
envío de la información.
Remoto
Los datos deben quedar alojados en dependencias
alejadas de la empresa.
<!--[if !supportLists]-->§ <!--[endif]-->Mantención de versiones
anteriores de los datos
Se debe contar con un sistema que permita la
recuperación de versiones diarias, semanales y mensuales de los datos.
Hoy en día los sistemas de respaldo de información
online (Servicio
de backup remoto) están ganando terreno en las empresas y
organismos gubernamentales. La mayoría de los sistemas modernos de respaldo de
información online cuentan con las máximas medidas de seguridad y
disponibilidad de datos. Estos sistemas permiten a las empresas crecer en
volumen de información sin tener que estar preocupados de aumentar su dotación
física de servidores y sistemas de almacenamiento.
Consideraciones
de software
Tener instalado en la máquina únicamente el
software necesario reduce riesgos. Así mismo tener controlado el software
asegura la calidad de la procedencia del mismo (el software obtenido de forma
ilegal o sin garantías aumenta los riesgos
Consideraciones
de una red
Los puntos de entrada en la red son generalmente el
correo, las páginas web y la entrada de ficheros desde discos, o de ordenadores ajenos,
como portátiles.
Mantener al máximo el número de recursos de red
sólo en modo lectura, impide que ordenadores infectados propaguen virus. En el
mismo sentido se pueden reducir los permisos de los usuarios al mínimo.
Se pueden centralizar los datos de forma que
detectores de virus en modo batch puedan trabajar durante el tiempo inactivo de
las máquinas.
Controlar y monitorizar el acceso a Internet puede
detectar, en fases de recuperación, cómo se ha introducido el virus.
Organismos
oficiales de seguridad informática
Existen organismos oficiales encargados de asegurar
servicios de prevención de riesgos y asistencia a los tratamientos de
incidencias, tales como el CERT/CC (Computer Emergency
Response Team Coordination Center) del SEI (Software Engineering
Institute) de la Carnegie Mellon University el cual es un centro de alerta y
reacción frente a los ataques informáticos, destinados a las empresas o
administradores, pero generalmente estas informaciones son accesibles a todo el
mundo.
Impacto de las redes en la
sociedad:
Internet tiene un impacto profundo
en el mundo laboral, el ocio y el conocimiento a nivel mundial. Gracias a
la web, millones de personas tienen acceso fácil e inmediato a una cantidad
extensa y diversa de información en línea. Un ejemplo de esto
es el desarrollo y la distribución de colaboración del software de
Free/Libre/Open-Source (FLOSS) por ejemplo GNU, Linux, Mozilla y OpenOffice.org
Comparado a las enciclopedias y a las bibliotecas tradicionales, la web ha
permitido una descentralización repentina y extrema de la información y de los
datos. Algunas compañías e individuos han adoptado el uso de los weblogs,
que se utilizan en gran parte como diarios actualizables. Algunas
organizaciones comerciales animan a su personal para incorporar sus áreas de
especialización en sus sitios, con la esperanza de que impresionen a los
visitantes con conocimiento experto e información libre. Internet ha llegado a
gran parte de los hogares y de las empresas de los países ricos. En este
aspecto se ha abierto unabrecha digital con los países pobres, en
los cuales la penetración de Internet y las nuevas tecnologías es muy limitada
para las personas. No obstante, en el transcurso del tiempo se ha venido
extendiendo el acceso a Internet en casi todas las regiones del mundo, de modo
que es relativamente sencillo encontrar por lo menos 2 computadoras conectadas
en regiones remotas
Desde una perspectiva cultural
del conocimiento, Internet ha sido una ventaja y una responsabilidad. Para la
gente que está interesada en otras culturas, la red de redes proporciona una
cantidad significativa de información y de una interactividad que sería
inasequible de otra manera
Internet entró como una herramienta de
globalización, poniendo fin al aislamiento de culturas. Debido a su rápida
masificación e incorporación en la vida del ser humano, el espacio virtual es
actualizado constantemente de información, fidedigna o irrelevante